TL;DR
- If you’ve ever needed a way to pull a bunch of content from your website I have a way to do that!
- Screaming Frog has a ton of functionality, their Custom Extraction/Search are some of my favorites.
- Use these Xpaths to get started with website scraping and analysis.
Digital marketers and SEOs often need to see what content looks like across a website. For smaller sites, it is possible to do this manually, for larger e-commerce sites you may need to do it with a tool like Python or Screaming Frog. There are some great scraping tutorials using Python from Greg Bernhardt and JC Chouinard, but I will use Screaming Frog & Xpath to extract content from a website for this process.
We are doing this as ethical digital marketers. I use this process to find e-commerce product descriptions, templated snippets of content like boilerplates, and other similar tasks. Do not use this to steal and spin junk content that muddies the waters, no one likes people who do that, just ask the writers at the Verge.
Use Xpath To Get Content Across An Entire Site (Or Section)
There is no one way to use XPath, it really comes down to how the website and HTML are structured. Below I will cover a few different ways to scrape content from websites to show how it may take some trial and error to get the right setup. It is possible there is one way or a solid broad way to get content, but these 4 have always worked for me so I thought I would share.
I recommend having the Chrome Scraper Extension installed so that you can test your Xpaths before crawling with Screaming Frog. Below you will see 4 different ways to extract content:
- Class
- ID
- Text After Elements
- Text Between Elements – More specific if the above version pulls too much.
You can also inspect an element and right-click to copy the XPath, but this way hasn’t always resulted in a broad enough way to get content site-wide. But test it out and see what happens.
Visit the links below and copy the Xpaths I provided, add in the unique portions that I call out in the screenshots and see how the scraping works. Find some other sites to test it out on, like I said they are not always the same. For example on Digital E-A-T’s, the Scrape After Elements pulls too much, but Scrape Between Elements cleans it up.
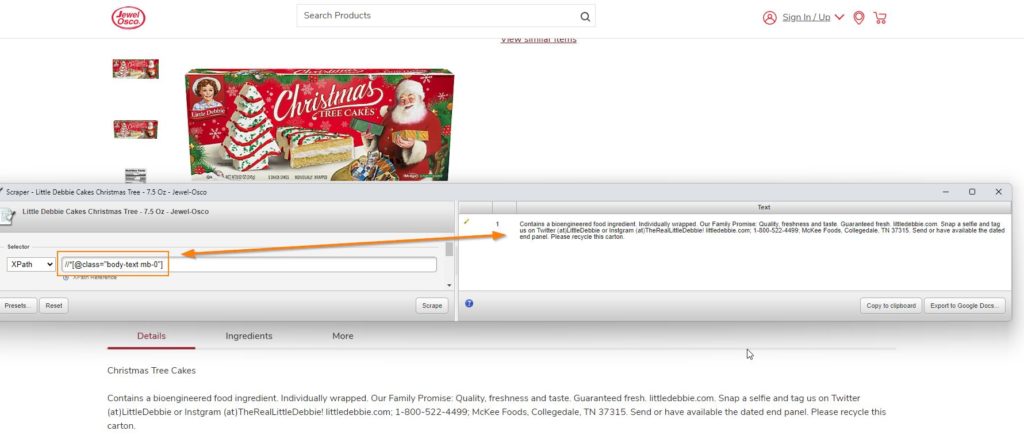
.Class – //*[@class=”Insert Class”] – Chrismas Cakes which are awesome!
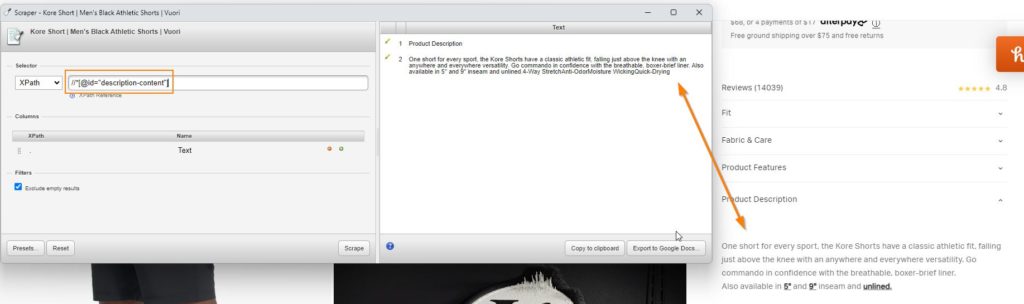
#id – //*[@id=”Insert Id”] – Vuori Shorts which I highly recommend!
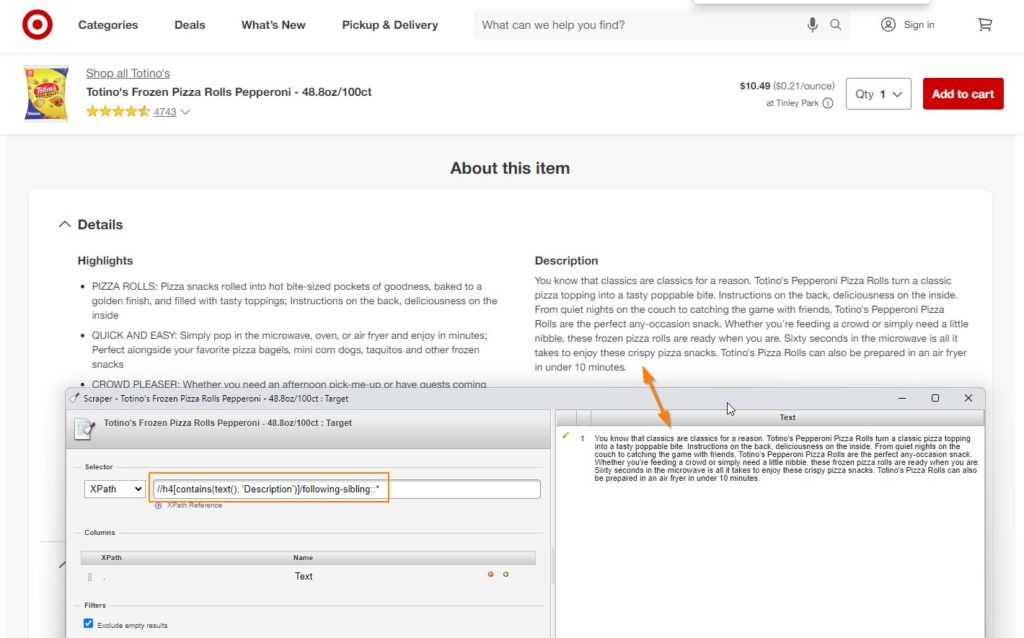
Text after element – //*[text()=”Insert Headline 1″]/following-sibling::* – Pizza Rolls, I don’t need to hype these up, they speak for themselves.
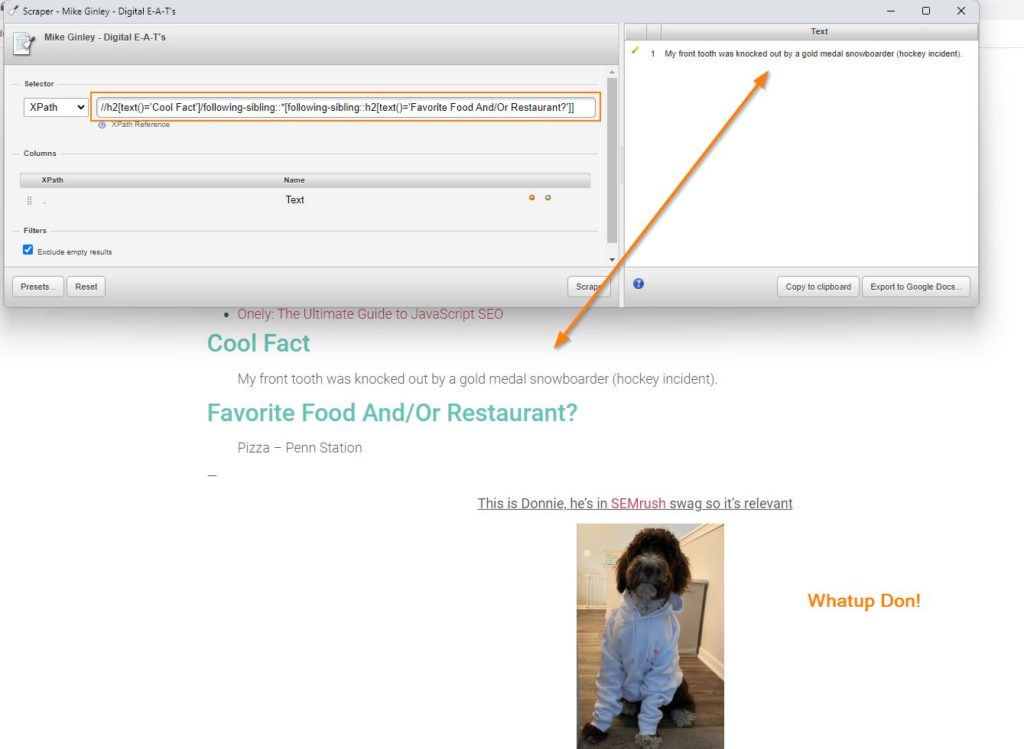
Text between elements – //h2[text()=’Insert Headline 1′]/following-sibling::*[following-sibling::h2[text()=’Insert Headline 2′]] – Digital E-A-T’s, reach out for a profile!
After we test these Xpaths out with the Chrome Scraper Extension we can toss them into Screaming Frog under Configuration > Extraction.
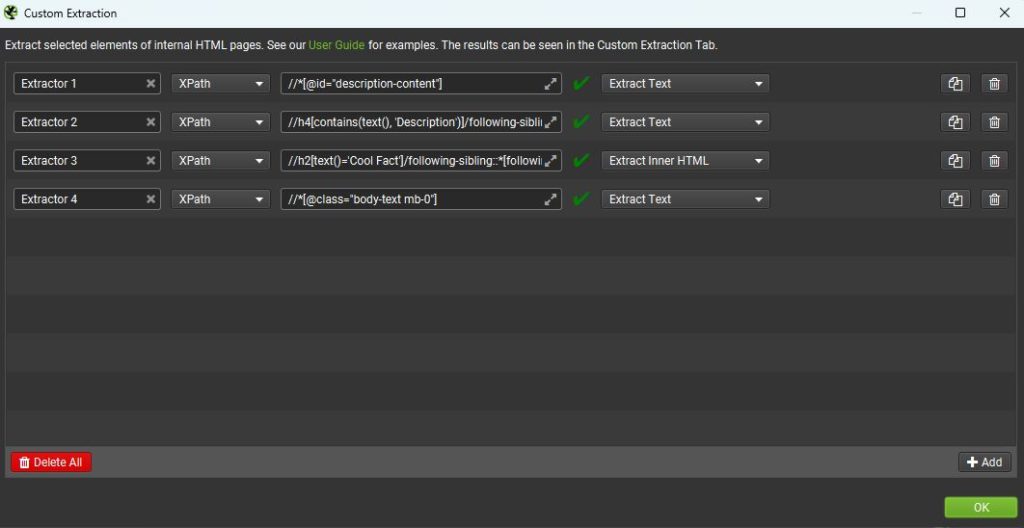
How To Use These Findings
When you use Screaming Frog like we did above you will see under the Extraction tab if content is being pulled. I recommend testing with a small sample of URLs before letting it go too far just in case the Xpath isn’t correct.
Below are the results from our examples above. As you can see we can export all these extractions into a spreadsheet for further analysis. Right now its pretty messy because they are 4 different sites, but I added another Target URL to show that we can pull the product description for multiple pages easily. Now we can review a large e-commerce website’s product descriptions to see how thorough they are. Maybe we are missing important information, maybe there is way too much content burying key elements. This gives us all the information in one place for further analysis.
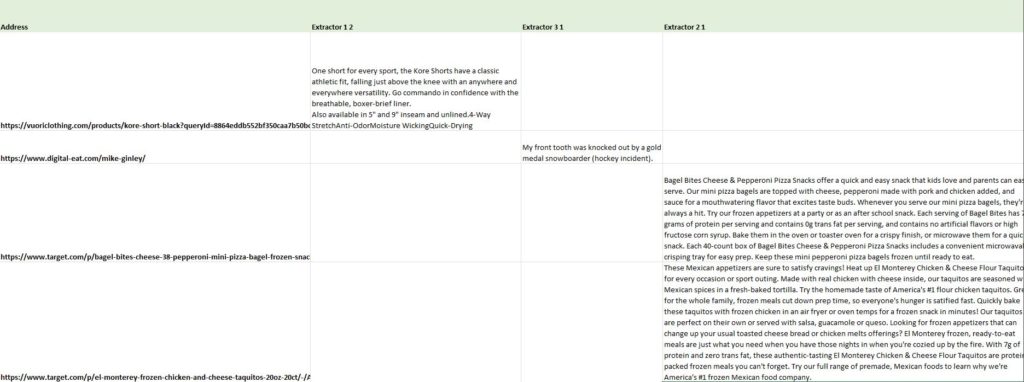
I have also used this process to scrape e-commerce product details that are out of date, missing or just incorrect. When we pull any specifications, descriptions or any templated content we can get it into a spreadsheet for further breakdowns. This can be so helpful with larger sites where it would take forever to do this manually.
Give these a shot and let me know how they work. If you are looking for more digital marketing, SEO or analytics help you can always reach out to me!



